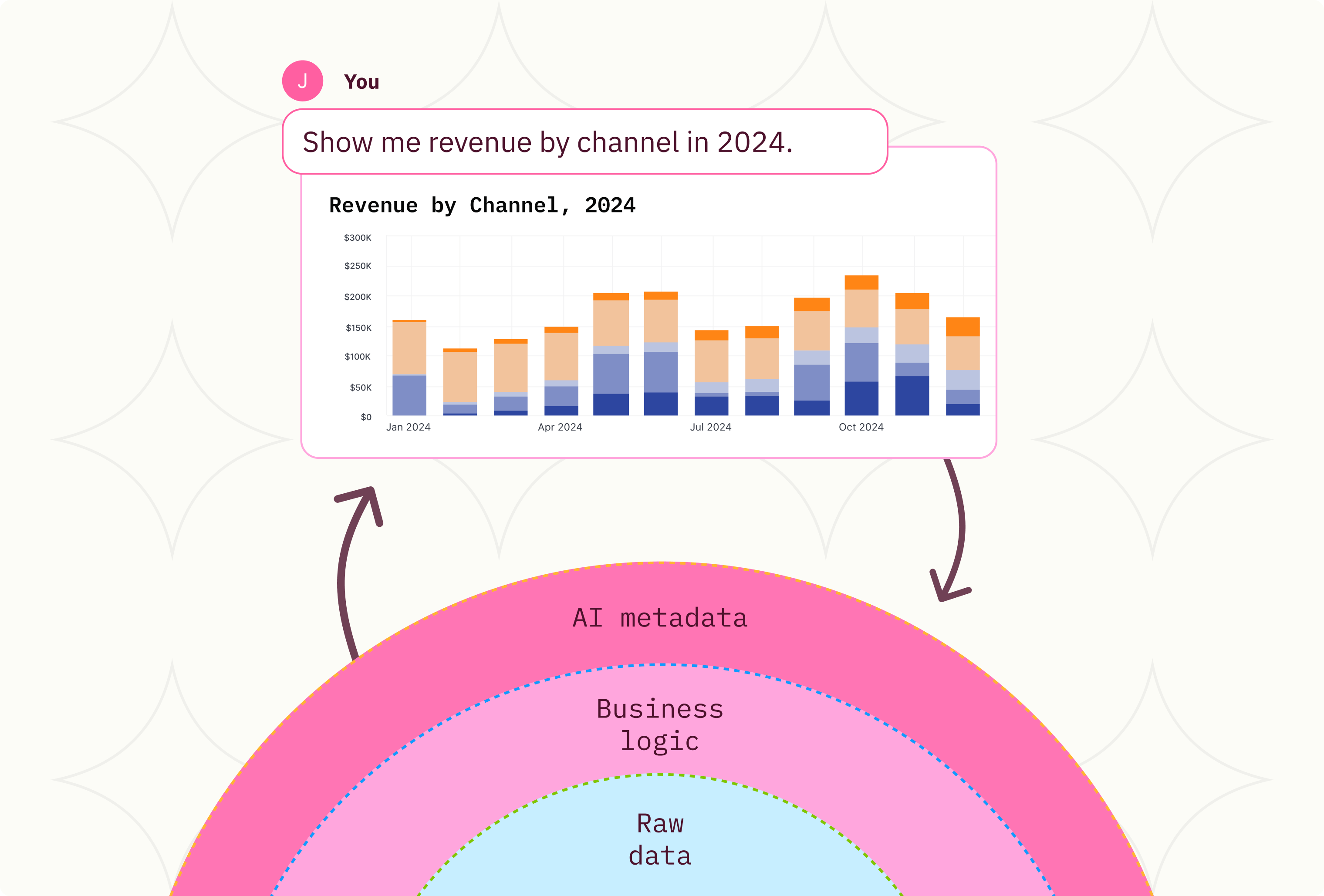
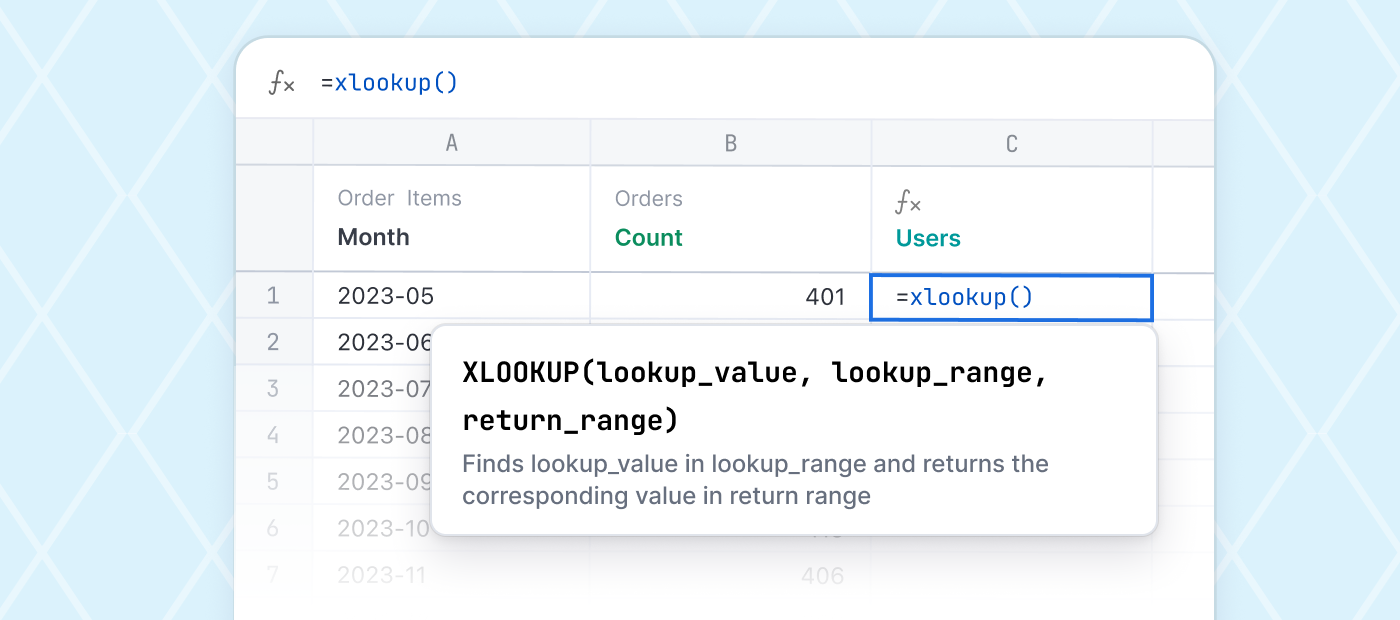
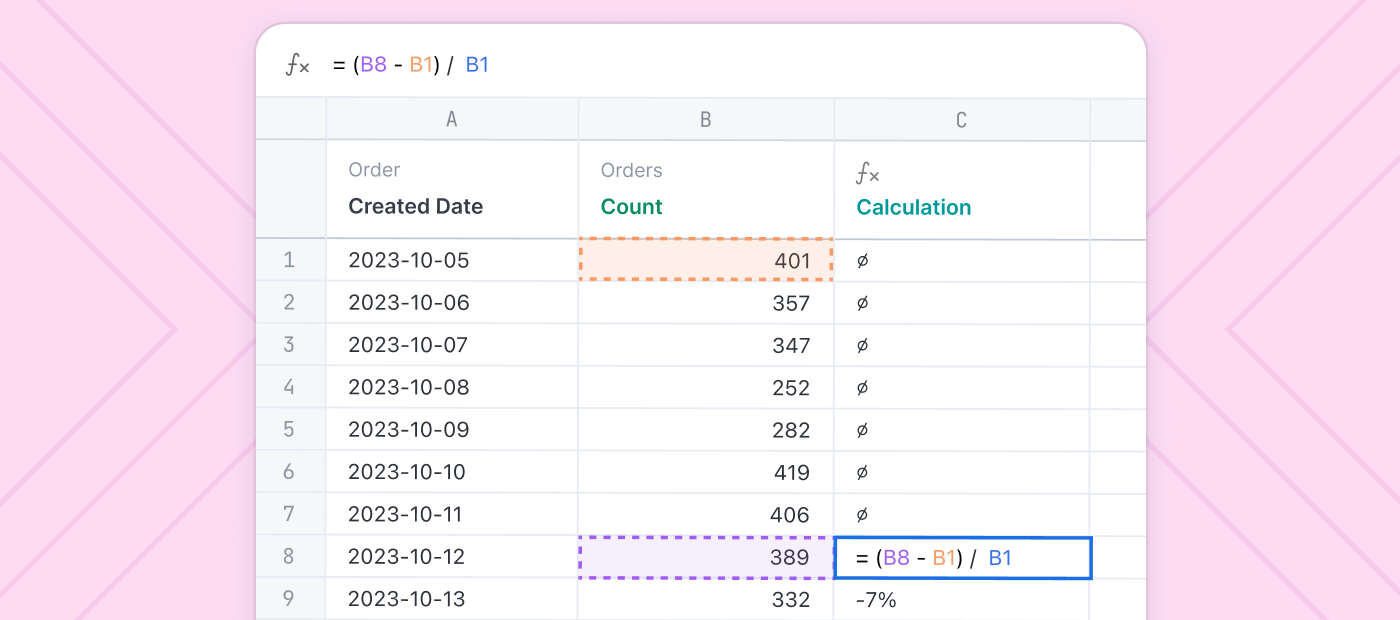
A data model is an abstraction that helps you properly understand and use data. Tables and columns in a database, the formatting and parsing expressions for application logs, and the logic connecting events in a stream are all examples of data models. So, it’s metadata? Not quite. A data model includes metadata like names, descriptions, and datatypes, but it is also an actual software abstraction that exposes a consistent interface, enforce constraints, and encapsulate logic.
Prior to Omni, I was the CTO of Stitch, an ETL (or ELT) company, which was acquired by Talend, another ETL company. Living in that world for nearly a decade, I thought about the database as the data model; our job was to deliver data with the best possible data model using the structure and features of the database. We primarily targeted SQL databases like Redshift, Snowflake, and BigQuery, which offer a nice set of features for data modeling: schemas, tables, and columns for naming and organization, constraints like uniqueness, and views to abstract complex transformation logic.
Data can be difficult to understand. #
But no matter how much effort we put into building descriptive and intuitive database structures, our customers always found the data difficult to understand and use. The table and column names and key definitions couldn’t explain which filters and groups make business sense, or that one dataset joins to another through the id field most of the time but sometimes you need to fall back to the email field, or that aggregating a dataset by day is misleading because it is generated weekly. In other words, database structures are great for describing the controlled world of a dataset that was created in the same database, but they break down when trying to describe the messiness that comes with handling outside data or real business logic.
Recently, dbt has leaned into the database-as-a-model concept by offering tools and workflows to make in-database modeling easier. Using dbt, users can encode complex business and data cleansing logic by hiding it in a view definition or table creation statement. But this creates a new problem: inevitably this logic will need to be spread across many views designed to serve different use cases, and when a new question is asked, a new view may be needed to serve it. dbt’s features offer help to manage this complexity, but it isn’t seamless: usually dbt is managed by analytics engineers with technical expertise, so a business user with a new question is dependent on them to create the dataset before getting answers. In other words, there’s a hard separation between model creation and model consumption.
How we think about it. #
The data modeling capabilities we are building in Omni are focused on helping people understand and collaborate with data. This means experts can codify how to use data and then hand it off to others knowing they will use it correctly, while non-experts have enough freedom and flexibility to explore not just their first question, but also the dozens of inevitable follow ups. It also means tight integration between the data model, visualization and exploration experiences so the model can guide exploration toward known paths, and explorers can incorporate new paths back into the model seamlessly.
Here are some of the other data modeling features we are building beyond the basics provided by the database:
Rich data types tell you that it’s an email address not just a string, or a dollar amount not just a decimal.
Naming and organization promote consistency, for example by only allowing a single definition of revenue to be used across all departments, or with tagging to indicate a model has been validated.
Abstraction and encapsulation to create simple interfaces for consuming data and hide complex transformation logic. For example, creating a single payments dataset that combines the data from three different payment providers. While database views are a form of this, they don’t cleanly handle use cases like common filtering logic that should apply to many data sets, or creating multiple time interval rollups of the same dataset (e.g. a report that can be viewed both monthly and quarterly).
Automated optimization of frequently used data to, for example, pre-materialize frequently used rollups, pre-warm caches with data that is likely to be needed, or identify duplicate logic across different data sets.
Tight integration with consumption workflows like data exploration and reporting to enable the model to not only understand datasets but also scheduling and interactions with data.
This list is just the tip of the iceberg - there are dozens of other ways we expect Omni to help users understand and collaborate on their data. We are going to be laser focused on this topic for a long time, and we can’t wait to show you how it’s shaping up.
If this sounds like an interesting problem to solve, we are hiring for all engineering roles. Join us us to build the business intelligence platform that combines the consistency of a shared data model with the freedom of SQL.