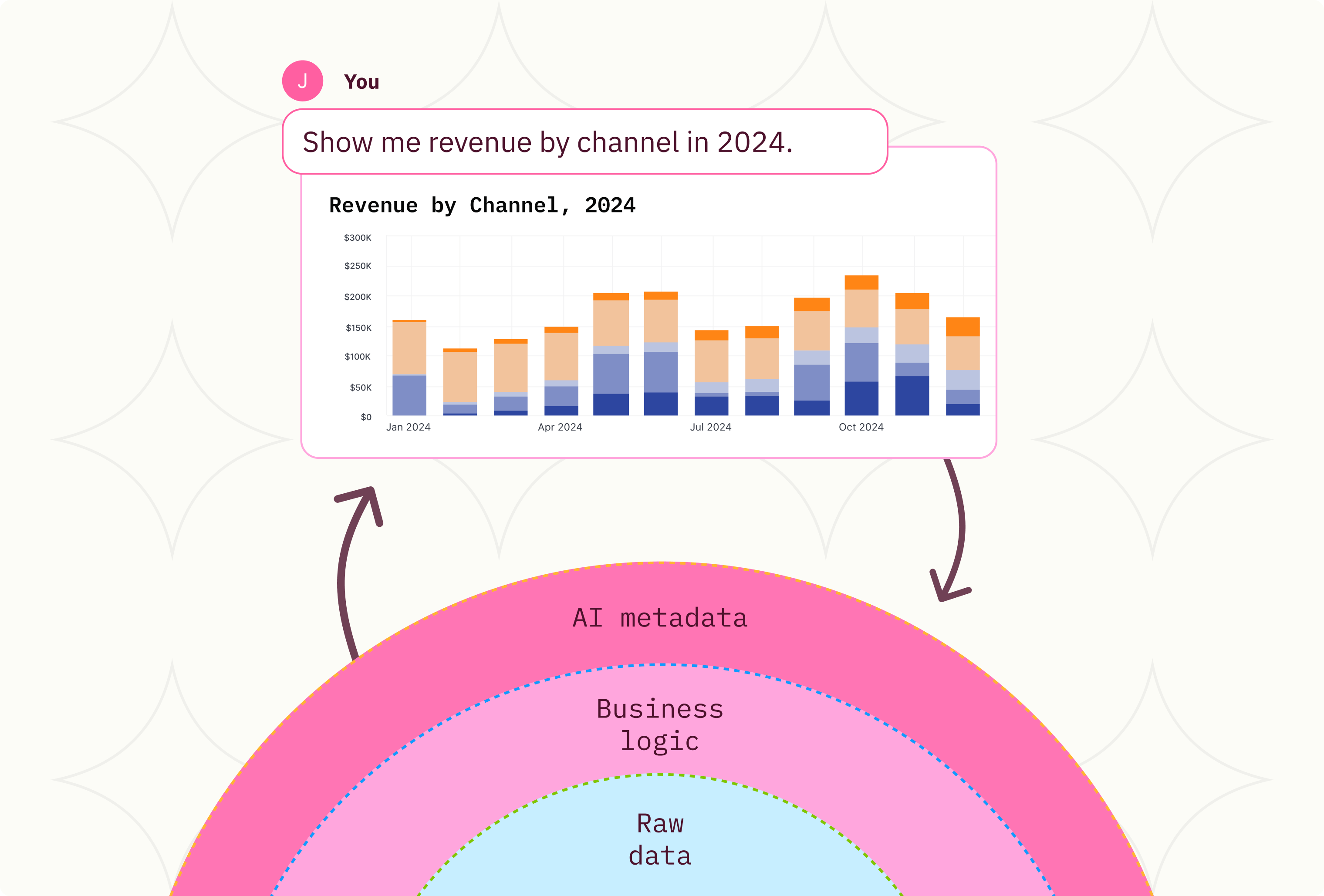
dbt has been the most significant improvement to the cloud data warehouse since the growth of Snowflake and BigQuery. We take a look at the rise of dbt, what makes it so powerful and the right ways to complement dbt in the data stack.
Simplicity of SQL #
The elegance of dbt lies in its simplicity – the API in and out is SQL. In many ways this is the core superpower of dbt. If you have a database, dbt can seamlessly attach and add value without disrupting any workflows upstream or downstream of the data warehouse. This means providing any improvement to a data team’s workflow presents an opportunity to incorporate dbt – no new language, no proprietary data format, no new API to call. Pairing this with the free price point of dbt open source (de-risking lock in and allowing easy trial), and you have a simple, clean value-add.
Community support #
Beyond this simplicity of implementation, the other superpower of dbt is its community, and the workflows and best practices they continue to develop. Software is never the complete solution to a problem. The workflow around how a product is implemented is often equally important to the code itself. So beyond the templating and scheduling that supercharge the database, the ability to bring deployment strategy and analytics expertise to business problems are reinforced by the dbt community. This means beyond the core technology, dbt has been able to bring a modeling style to bear on cloud data warehouses – this reinforces dbt stickiness, and also extends what the software can accomplish to the expertise of early adopters.
SQL is naive #
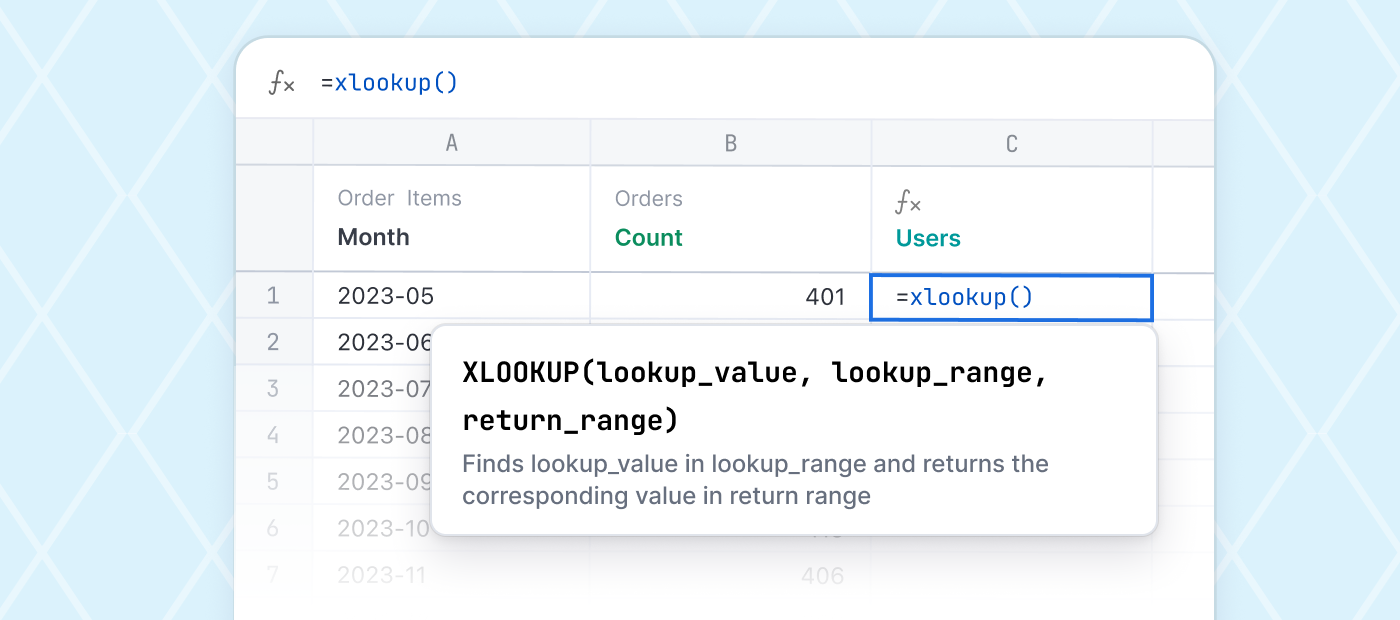
For all dbt’s strengths, it’s also helpful to frame the gaps with dbt in isolation. The core strength of dbt is the simplicity of the APIs – SQL in and SQL out. SQL’s ubiquity is unchallenged, and cloud data warehouses have become the core for data consumption in nearly all mature businesses. But SQL is disconnected from consumption layers above it like dashboards and analytics tools – SQL is naive to how it’s consumed by end users. This naivety enables the ease of implementing dbt, but it also distances the dbt model from its ultimate consumption by end users. SQL cannot natively pass that context and metadata, even though that data is crucial to evolving and improving the data sets beneath. What data is being consumed? What data sets need to be optimized for cost and performance? How can we improve freshness or context for end users? SQL cannot be that interface, so the consumption layer above needs to fill that gap.
Second, while the community can provide enormous leverage into the creation of patterns and analytics, agility and responsiveness to the organization is the most important feature of an effective data team. Businesses are fluid – new data is evolving constantly, user needs shift over time, and rarely can a service org stay in front of each department’s needs. The most effective data teams are able to publish flexible environments, monitor consumption, and constantly improve the speed, cost, and quality of data sets. While legacy data stacks often sacrificed accessibility, either publishing blessed data or simply driving questions into queues served by data analysts, users have become more comfortable self-serving requests or consuming data in source systems.
How fast is too fast? #
All of dbt’s strengths have led to a publisher model for data – environments where manicured analytics-ready data sets are promoted to the organization after significant grooming from the data team (not unlike the golden age of OLAP cubing). And this model works in many cases, but business logic will not always be known in advance (or at least not codified readily). Taking this pattern too far is already leading to costly back and forth between data users and data set builders as data changes and new questions are asked of the data.
There are many applications for the productization of data, but this needs to be one of many models for how data is consumed. Servicing an org with data is evolutionary – first create availability - publish [usually raw] data sets and allow users to draw insight. In response data teams can then optimize and promote business logic from just-in-time layers consumption layers (BI tools or data models inside BI tools) deeper in the data stack to materialization layers (dbt or ETL pipelines). Fluidity between how data is consumed, latency, and the effort to prepare data must all be balanced constantly.
If users are waiting for perfect data sets, data teams are moving too slow (lots of parallels to building great product). New tools will embrace this motion without introducing rigid experiences to end users. The visualization layer will always remain the primary vehicle for creating and understanding metrics, but it needs to interface far better with the transformation tools below.
We’re aiming to build a dbt partner that leans into the core strengths of the platform – simple, SQL-driven transformation – while providing more fluidity for end users to work with raw, low-latency, complete data. Our vision is to rapidly deliver data to end users and data teams, allowing any user to ask any question, and harden core workflows and data sets over time, with seamless performance optimization, and elegant integration into lower level services. In this paradigm of modeling-by-doing, data teams will be unbound from the constraint of delivering data and can focus on value-added analyses and refining pre-existing data sets rather than the data breadlines that can form behind rollup building. Give Omni a try and tell us what you think.
If this sounds like an interesting problem to solve, we are hiring for all engineering roles. Join us us to build the business intelligence platform that combines the consistency of a shared data model with the freedom of SQL.